In der letzten Topfprimel war ja schon kurz die Rede davon: Irgendwann im Januar hat es auch blickgewinkelt erwischt und unser Blog wurde kopiert, oder genauer wurde unser Blog „geklont“.
Da bisher wohl tendenziell eher WordPress-basierte blogs betroffen waren, blickgewinkelt aber bis vor kurzem noch bei blogger.com / blogspot zu Hause war, haben die im Netz kursierenden Anleitungen gegen den Blog-Klon für uns nur teilweise funktioniert. Da das Problem immer wieder mal auftaucht und deshalb zwischendurch auch mal die eine oder andere Frage eintrudelt wie man in dem Fall denn reagieren kann, schreibe ich einfach mal auf was wir getan haben um das Problem (zumindest erstmal, toitoitoi!) loszuwerden.
Gleich vorweg: Dieser Beitrag ist keine Anleitung die in jedem Fall und immer funktioniert, und einige der Maßnahmen die wir hier getroffen haben erfordern auch Kenntnisse die vielleicht weder von jedem angewendet werden können noch sollten.
Ich hoffe mal, dass das jetzt nicht unter „elitäres Administratorengelaber“ verbucht wird – ich will das nur vorwegschicken, damit sich nicht jemand aus Versehen seinen Server zerschießt. Lieber mit einer schlechten Kopie eures funktionierenden Blogs leben, als mit der veralteten Kopie eures ehemaligen und nicht mehr erreichbaren Blogs! Im übrigen gibt es neben diesen technischen Dingen auch noch ein paar nicht-technische Dinge, die ihr als Betroffene unternehmen könnt (und solltet).
Klonen? Was ist das überhaupt?
Beim Klonen eines Blogs versucht jemand die Inhalte eines kompletten Blogs (oder einer Website) zu übernehmen.
Und zwar nicht in der Form, dass einzelne Artikel geklaut und (leicht umformuliert) als eigene Inhalte verkauft werden, sondern eine wirklich vollständige Kopie aller Texte, Bilder, und des Layouts. Manchmal werden dann noch ein paar Daten verändert, wie z.B. der Name des Blogs, der Name der Autorin/des Autors, oder der Inhalt des Impressums. Der ganze Rest wird komplett geklaut und entweder unter einem anderen Namen („blickgewinkelt.de“ vs. „tina-travel.com“), oder manchmal auch einem sehr ähnlich klingenden Namen (z.B. „blickgewinkelt.de“ statt „blickgewinkelt.de“) veröffentlicht. In unserem Fall sah das dann so aus:
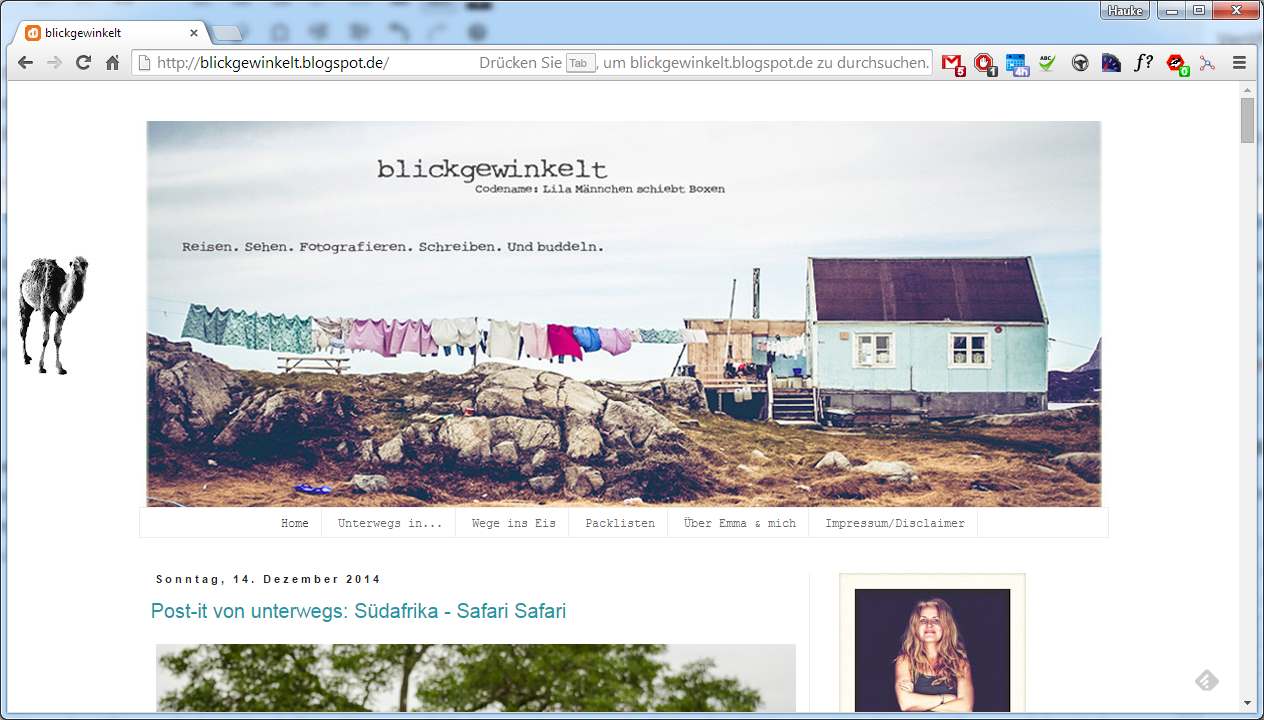 blickgewinkelt: Das Original | 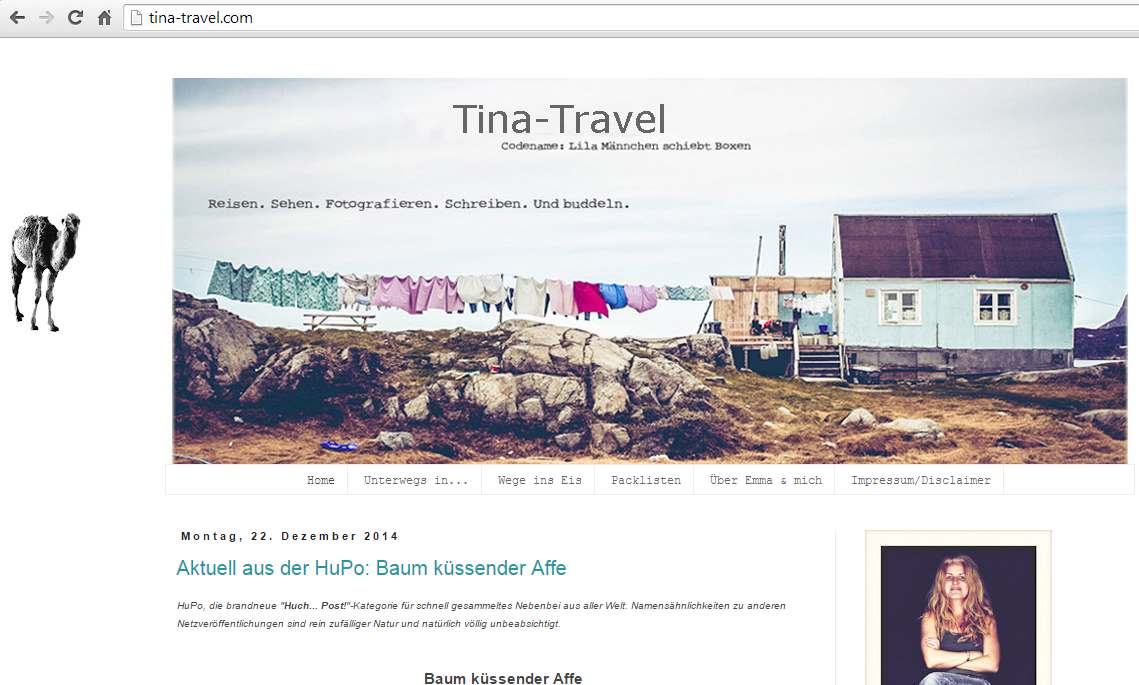 … und hier die schechte Kopie. Buuuuh! |
Und wieso macht jemand sowas?
Letztlich geht es den Clowns (hah! Schenkelklopf!) vermutlich darum, eine vermeintlich echte Website mit Leben zu füllen, und damit dann über Affiliate Links (und womöglich andere Werbeformen) Einnahmen zu generieren. Soweit ist es bei uns gar nicht erst gekommen, was vermutlich daran lag, dass wir es schnell genug bemerkt haben.
Wie bemerke ich, dass ich geklont werde?
Wir haben es dadurch gemerkt, dass wir eine Google Suche nach „Topfprimel“ gemacht haben (blickgewinkelt ist quasi DIE weltweite Autorität in Sachen Topfprimeln, echt wahr jetzt! ).
Die Suche nach einem Klon kann man auch automatisieren, mehr dazu weiter unten.
Kann mir so eine Blog-Kopie im Netz nicht völlig schnuppe sein?
Klar, das kann es natürlich. Wenn euch eure Botschaft wichtiger als alles andere ist, dann könnte man natürlich argumentieren und sagen „je mehr Leute mein Statement zum Klimawandel lesen, desto besser“. Mir persönlich kringeln sich zwar beim Gedanken daran, dass da jemand mit meiner Arbeit, aber ohne meine Einwilligung Geld macht die Fussnägel hoch, aber das ist vielleicht ja auch nur eine Charakterfrage :)
Ab wann ein solcher Klon sich auch negativ auf euer Google Ranking auswirkt (Stichwort double content) – hmm, dafür bin ich nicht Experte genug. Spätestens dann, wenn der Klon noch vor euch bei einer Google Suche erscheint wird es aber in jedem Fall ärgerlich, denn dann landen die Leser ja nicht mehr bei euch, sondern beim Klon.
Blöde wird es natürlich, wenn auf dem Klon „eures“ Blogs unter eurem Bild dann Sachen auftauchen mit denen ihr nichts zu tun haben wollt, z.B. Werbung für irgendwelche dubiosen Kreditmakler, P**no-Seiten oder was auch immer. Spätestens dann sollte es einem nicht mehr egal sein.
Wie funktioniert das Klonen technisch?
Uhh, da muss ich ein bisschen raten, weil wir leider in der Eile damals nicht wirklich tiefgreifende Analysen gemacht haben. Ich tippe aber mal sehr darauf, dass zumindest bei uns die Kopie „on the fly“ erstellt wurde. D.h., der User tippt „tina-travel.com“ ein, der böse Clown greift auf eure Inhalte zu, ersetzt ein paar Stichwörter (Namen), ersetzt auch einige Links (z.B. auf das Titelbild) und liefert das dann als Ergebnis aus. Das hält den Aufwand für den Dieb in Grenzen, denn er muss nur einmal die Ersetzungsregeln definieren, und bekommt danach automatisch immer frei Haus die aktuellen Inhalte von euch geliefert. Und er muss auch nicht eine komplette Kopie auf seinem eigenen Rechner vorhalten und ständig aktualisieren.
Natürlich ist es aber auch möglich einfach eine komplette Kopie eures Blogs zu ziehen und woanders abzuspeichern.
Sauerei! Was kann ich tun?
Aus meiner Sicht unterteilt sich das in zwei Gruppen: die Technischen-, und die (ich nenne sie mal so) Administrativen Maßnahmen.
Letzteres kann eigentlich jeder machen und das sind wohl auch die vermutlich wirklich effektiven Schritte die dann bei uns dazu geführt haben dass der Clown seines Weges gegangen ist. Zumindest den Punkt 1 sollte aber JEDER Betroffene machen.
- Screenshots anfertigen (auch vom Impressum!)
- Den
Scraper Reportbei google ausfüllen: Damit kann man google mitteilen, dass Seite A von Seite B Inhalte kopiert. Man kann zumindest hoffen, dass google die Seite dann irgendwann mal aus seinem Index rauswirft. Hinweis: die entsprechend Seite scheint nicht mehr vorhanden zu sein. - Einen DMCA-Complaint bei Google einreichen: Wenn man sich ganz sicher ist im Recht zu sein kann man bei Google eine Urheberrechtsverletzungen melden. Aber Achtung, dort wird nach amerikanischem Copyright „geurteilt“, d.h. dass z.B. kleine Kopien von Textpassagen evtl. unter „Fair Use“ fallen und keine Verletzung des Urheberrechts darstellen – ich bin kein Anwalt. Wenn allerdings jemand eine komplett-Kopie eines Blogs inkl. aller Bilder anfertigt, dann dürfte das wohl überall illegal sein.
Hinweis: Wir haben das „damals“ nicht gemacht weil wir die entsprechende Seite nicht kannten. Es scheint mir aber ganz sinnvoll zu sein um die Suchergebnisse bei google bereinigt zu bekommen. - Herausfinden, wer der Betreiber der Seite ist. Das geht z.B. indem man mal schaut, auf wen die Seite registriert ist, z.B. unter whois.domaintools.com. Dummerweise sind die dort hinterlegten Angaben mit 99%-iger Sicherheit falsch – der Dieb wäre ja auch schön blöd, wenn er da seine eigene Adresse hinterlassen würde. Aber zumindest zwecks Beweissicherung kann es nicht schaden sich das (möglichst zu zweit) anzuschauen und ein paar Screenshots anzufertigen und auszudrucken. Datum nicht vergessen!
- Fast immer ist der Domain-Registrar (also die Firma, bei der der Dieb den Namen der Seite registriert hat) die Firma godaddy.com. Ja, der Name klingt einigermaßen schmierig. Und warum die Kloner alle bei denen landen … tja. Häufig verstecken die Kloner die eigentliche Adresse ihres Servers dann auch noch hinter einem Reverse Proxy wie Cloudflare, d.h. man erfährt also noch nicht mal bei welchem Service Provider der Rechner nun eigentlich steht. In dem Fall kann man dann versuchen, sich bei Cloudflare zu melden, die wiederum *sollten* dann den eigentlichen Betreiber des Servers ansprechen und ihn auffordern sein schändliches Handeln (echtmal jetzt!) einzustellen. Ob sie das dann auch wirklich tun … tja, wer weiß?! Wir haben zumindest noch am selben Tag eine Antwort bekommen dass sie den Betreiber entsprechend benachrichtigt hätten.
- Die größeren Affiliate Link Firmen (z.B. Zanox und tradedoubler) informieren. Man kann sich dann der Hoffnung hingeben, dass die den Betreiber der Klon-Seite sperren und der aufgibt.
- Häufig wird auch empfohlen Strafanzeige zu erstatten. Das führt zwar quasi zwangsläufig zu einer Einstellung des Verfahrens, aber zumindest taucht die Straftat ja vielleicht mal in einer Statistik auf. Und Beweissicherung kann man dadurch natürlich auch betreiben.
Das reicht mir nicht!
Ich will zumindest virtuell kratzen, beißen und spucken!
Eine Anmerkung vorab:
Ich glaube nicht, dass es technisch überhaupt möglich ist das klonen eines Blogs wirklich sicher und endgültig zu verhindern (*). Wir Blogger stellen unsere Inhalte ins Netz damit sie möglichst stressfrei von unseren Lesern gelesen werden können, und das schließt bestimmte denkbare Schutzmaßnahmen aus. Zum Beispiel könnte man natürlich von seinen Lesern verlangen sich zu registrieren, um so zumindest mitzubekommen wer sich denn da immer munter bedient. Oder man könnte vor das Lesen ein Captcha schalten, aber … also ehrlich, dann kann man sein Blog ja auch gleich dichtmachen und erzählt der einzig verbleibenden Leserin (vermutlich Mutti) direkt was im Leben so vor sich geht. Das Internet ist dazu designed Informationen mit anderen Menschen zu teilen. Leider auch mit den bösen Menschen.
Wie bitte? Soll das heißen ich kann NICHTS machen?!
<Vorsicht, jetzt wird es sehr technisch. Sorry!>
Najaaaa … also ein bisschen ärgern können wir die bösen Jungs und Mädchen natürlich schon. Vielleicht haben wir Glück, und sie suchen sich danach jemand anderen den sie kopieren können. (Vielleicht aber auch nicht: Wenn Tina T. hier mitliest und sich jetzt ihrerseits herausgefordert fühlt, dann ist blickgewinkelt womöglich ab übermorgen weg vom Fenster. In dem Fall: Danke für die schöne Zeit mit euch! ;-)
Hier ist das was wir gemacht haben, allerdings empfehle ich dringend das nur dann zu versuchen, wenn ihr …
- ein (aktuelles!) Backup eures Blogs habt
- wisst was eine shell ist und wie man damit arbeitet
- euch klar ist, dass eine falsche rewrite condition in einer .htaccess zum GAU führen kann (zumindest wenn man nicht weiss wie man das auch rückgängig macht)
- HTML und ggfs. Javascript und php euch nicht völlig fremd sind
Mit anderen Worten: Überlegt es euch zweimal. Oder drei- bis viermal.
Aber da nun schon mal jemand gefragt hat … klar, irgendwas geht ja vielleicht doch! Und ich will ehrlich sein: Zugegebenermaßen war auch ein kleines bisschen Spaß, sportlicher Ehrgeiz und kindische Rachsucht beteiligt ;) Wir würden gerne folgendes erreichen:
- Der Leser sollte wissen, dass er sich auf einer Kopie befindet. Zumindest für die Affiliate Firmen kann das auch hilfreich sein um zu beweisen wer Original und wer Fälschung ist.
- Wenn möglich, dann sollte bei einem normalen Zugriff über die Original-URL alles so bleiben wie vorher.
- Wenn der Leser auf der Kopie unterwegs ist, dann soll er auf einen Klick hin zum Original kommen können.
- Am Besten wäre es wenn die Kopie einfach komplett unbrauchbar wäre.
Und so haben wir’s gemacht:
1) Wir haben Inkas Profilbild ausgetauscht und draufgeschrieben, dass nur unter blickgewinkelt.de das Original zu finden ist. Die Maßnahme kann eigentlich so ziemlich jeder gefahrlos vornehmen. Macht euer Blog aber natürlich auch irgendwie ein bisschen hässlich weil das Bild ja sowohl im Original, wie auch in der Kopie sichtbar ist.
 Originalzustand |  … und mit dezentem Hinweis. |
2) In unserem Fall kamen alle Anfragen von einem bestimmten Server, und wir hätten (wären wir schon bei WordPress auf unserem eigenen Server gewesen) dann z.B. Anfragen nach Bildern die von diesem Server kamen mit niedlichen Katzen-GIFs beantworten können. Dummerweise waren wir zu dem Zeitpunkt noch bei blogspot, da sind die Einflussmöglichkeiten geringer, und wir wollten auch nicht wirklich in ein paar hundert Artikeln die URLs der Bilder verändern. Da wir den eigenen Server aber schon hatten, ging zumindest folgendes: Wir haben im Quellcode der Seite (also im html) das hier eingebaut:
<img src="//unser.server.de/tina/empty.jpg" />
Da die Bilder ja (bis auf z.B. das Titelbild) nach wie vor von den Originalquellen geholt wurden, konnten wir auf „unser.server.de“ durch eine geeignete RewriteCond (den HTTP_REFERRER) in der .htaccess überprüfen ob die Anfrage nach dem Bild „empty.jpg“ nun von tina-travel ( = böse) oder blogspot ( = gut) kam. Kommt nun die Anfrage von blogspot, ist alles ok und wir liefern ein leeres weißes Pixel aus. Kommt sie aber von tina-travel.*, wird statt „empty.jpg“ unser berühmtes „tina_stinkt.jpg“ (**) zurückgeliefert, und der Leser der Seite sieht zumindest dass er da auf einer schlechten Kopie unterwegs ist.
[sourcecode language=“bash“ wraplines=“false“ collapse=“false“] RewriteCond %{HTTP_REFERER} !^$RewriteCond %{HTTP_REFERER} http://.*tina-travel.* [NC] RewriteRule .*empty.jpg /images/tina_stinkt.jpg [R,L] [/sourcecode]
Das führt dann bei einem Aufruf über die Klon-URL zu folgendem Ergebnis:
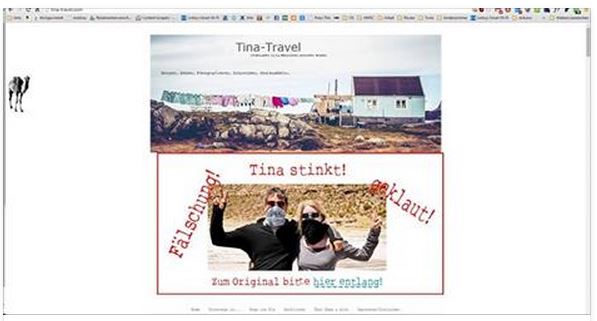
So sieht’s aus!
3) Von der Kopie zum Original springen: Was nicht funktioniert ist das oben gezeigte „tina_stinkt“ – Bild einfach mit einem Link zu versehen – der Klon ersetzt ja alle Verweise auf das Original durch Links auf sich selber. Der einfache Trick, der dann doch zum gewünschten Ergebnis führt: Statt „original.de“ verwenden wir einfach eine short URL, z.B. von goo.gl. Die wird vom Klon (nicht so einfach) als Verweis auf die Originalseite erkannt. Hah! In your face!
4) Die Kopie komplett unbrauchbar machen – das wäre evtl. gegangen wenn das Blog schon zu WordPress umgezogen gewesen wäre, in dem Fall hätten wir z.B. alle Anfragen mit dem falschen Referrer ins Leere laufen lassen. Ging aber nun mal nicht.
Wäre die Kopie nicht „on the fly“, sondern in regelmäßigen Abständen tatsächlich eine komplette Kopie aller Seiten hergestellt worden – zumindest auf dem eigenen Server hätte man dann mit Hilfe einer firewall und tools wie z.B. „fail2ban“ versuchen können solche scraper auszusperren. Ist aber ein bisschen tricky, man will ja nicht aus Versehen den Crawler von Google sperren.
Gegebenenfalls hätte man auch noch ein paar Zaubereien mit Javascript und CSS veranstalten können (ich hab‘ da so eine vage Idee), aber letztlich war das nicht nötig, weil tina-travel dichtgemacht wurde. (*** Oops: siehe Fußnote.)
Achja, was hilfreich sein kann um möglichst frühzeitig zu erkennen ob man selber betroffen ist: Man kann sich bei Google Alerts einen Alarm einstellen lassen, der einen benachrichtigt, wenn es zu einem bestimmten Thema was Neues gibt. Wenn nun ein markanter Satz eures Blogs plötzlich auf einer anderen Seite auftaucht, sollte man mal nachschauen wie der denn da hingekommen ist.
Abschließend sei nochmal betont: All das sind nur technische Spielereien, es ist ein Katz- und Maus-Spiel, und der Dieb ist letztlich (s.o.) immer leicht im Vorteil. Ob es also die Mühe überhaupt wert ist muss jeder selber wissen. Letztlich erfolgversprechender sind vermutlich die „Administrativen Schritte“.
Weiterführende Links:
Mit dem Problem müssen sich Blogger ja schon seit Jahren rumschlagen, und deshalb ist das hier natürlich auch weder der Weisheit letzter Schluss, noch enthält er Druidenwissen das man nur hier erlangen könnte. Wer sich weiter einlesen möchte (oder muss :-/ ) findet hier ein paar Links zum Thema:
– Alex Mirschel von niedblog.de hat schon vor einem halben Jahr einen Beitrag zu dem Thema auf seinem Blog veröffentlicht. Wir haben hier trotzdem nochmal unsere Vorgehensweise aufgeschrieben weil wie bereits erwähnt damals quasi nur WordPress-Blogs betroffen waren, blickgewinkelt aber bei blogspot lief. Trotzdem natürlich lesenswert!
– CopyScape ist eine Seite die versucht Duplikate einer Website zu finden. Habe ich nicht wirklich getestet, wäre aber mal einen Versuch wert.
– Es gibt eine (geschlossene) facebook-Gruppe zu dem Thema: Blog-Klons, Identitätsmissbrauch & Content-Diebstahl (Betroffene)
– Content scraper erkennen: http://www.javascriptkit.com/howto/htaccess13.shtml
Wie immer gilt auch hier: Ich freue mich sehr über Kommentare, Meinungen, Anregungen, Verbesserungsvorschläge usw. zu diesem Beitrag. Sicherheitshalber will ich in dem Fall aber noch anfügen, dass ich euch sowohl aus technischen als auch aus Zeitgründen kaum bei der Lösung eines konkreten Problems helfen kann. Ich bitte um Nachsicht!
/hauke
—–
Quellenangabe zum Schaf: http://commons.wikimedia.org/wiki/File:Lleyn_sheep.jpg
Vielen Dank an den Autor jackhynes für das freundliche zur Verfügung stellen.
(Übrigens musste ich gerade Lernen dass die Verbindung Schaf -> Klon offensichtlich nicht (mehr) funktioniert. Ich werde alt, seufz! Für alle die sich beim Betrachten des Titelbilds leicht grübelnd am Kopf gekratzt haben: hier der Link zu Wikipedia.)
(*) … aber ich lasse mich auch gerne eines besseren belehren! Wenn jemand einen Vorschlag hat, gerne ab damit in die Kommentare!
(**) Ich bitte alle Martinas, Christinas, Bettinas und was auch immer sonst noch es für -tinas auf dieser Welt geben mag um Verzeihung für das „Tina stinkt“. Ihr seid natürlich nicht gemeint gewesen!
(***) Und noch während ich gerade so schön am konzipieren des Artikels war habe ich bei einer erneuten Überprüfung von tina-travel.com festgestellt dass „tina“ jetzt doch wieder aktiv ist und sich ein neues Opfer gesucht hat. :-(
Falls ihr einen Klon findet: auch wenn es euch nicht betrifft, bitte benachrichtigt den Betreiber der Original-Seite! Er oder sie lässt sich meistens ganz leicht finden indem man nach einem spezifischen Satz aus dem Blog googelt. Der Besitzer der Originalseite wird es euch danken!
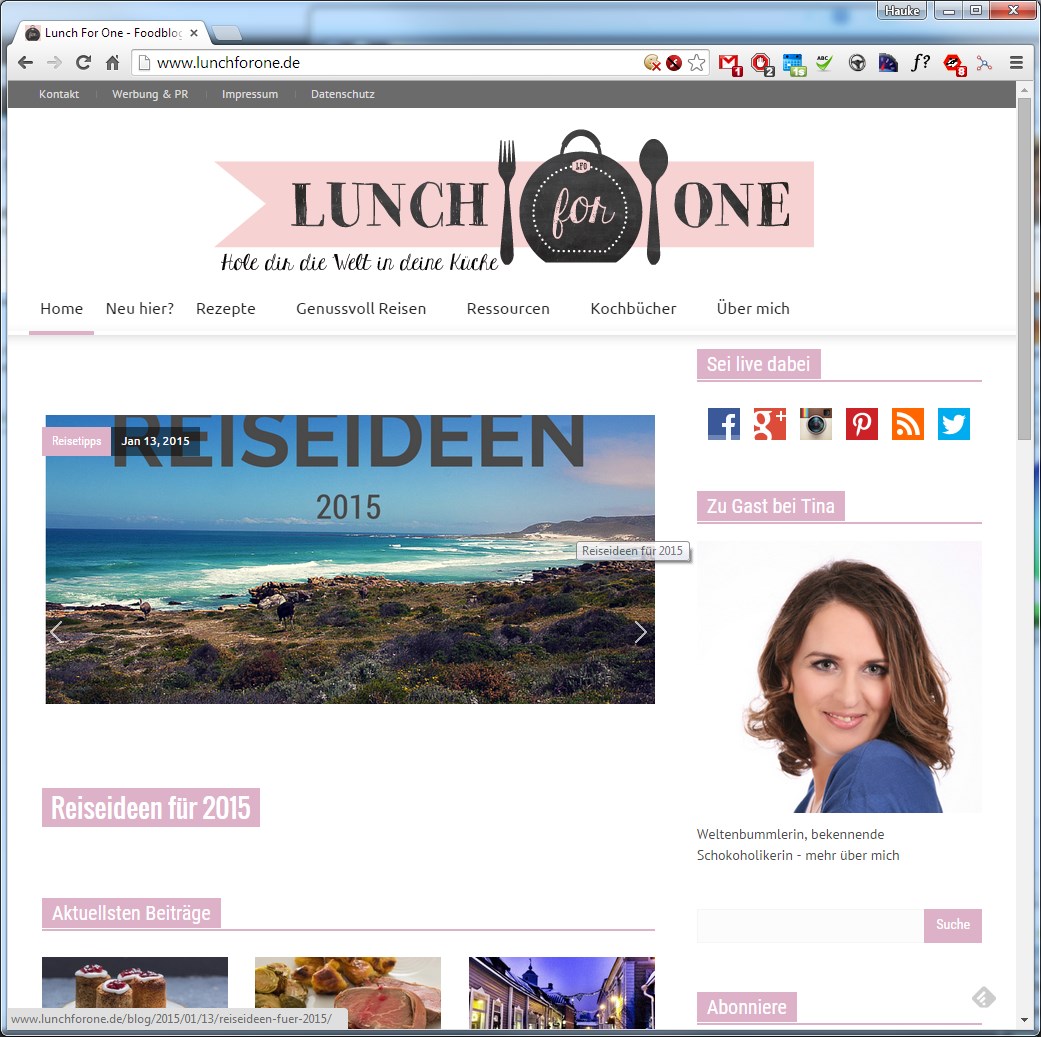 Noch ein Original … | 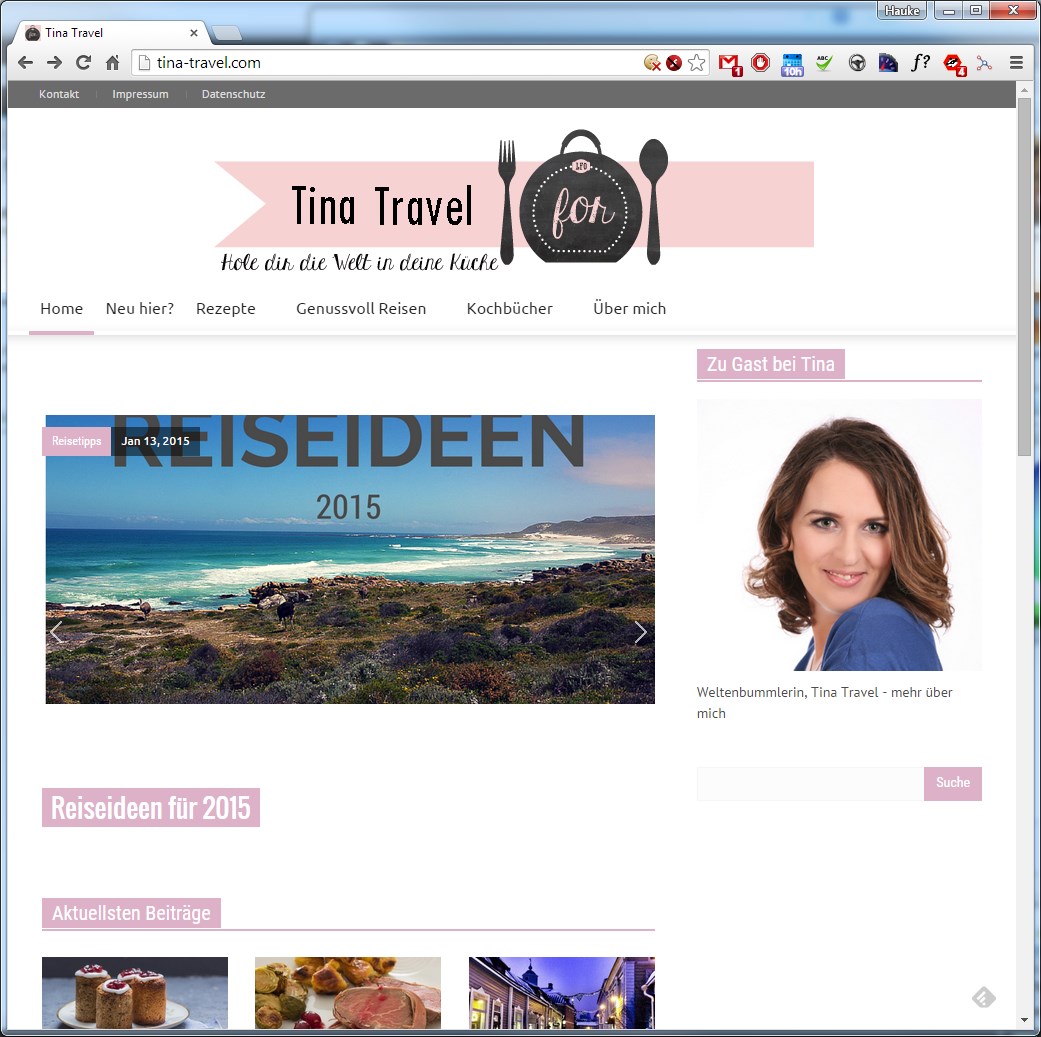 … und noch eine Fälschung! |


